3.2 Contexto académico y técnico de los datos
Los fines buscados con la disposición de las cifras en el escenario de las universidades públicas, las políticas, normas y los actores nacionales e internacionales que regulan la actividad estadística, los diversos alcances buscados a través de la gestión de los datos institucionales, así como el lenguaje derivado del modelo administrativo dominante al interior de las universidades conforman, como se presentó en la anterior sección, el contexto en el que se desenvuelve la actividad estadística en la universidad pública actual y define el primer componente que se debe conocer y explorar previo o durante la implementación de una apuesta institucional orientada a la gestión y disposición de las cifras cuantitativas disponibles.
Una vez se conoce y domina el contexto en el que se mueven las cifras cuantitativas requeridas en la universidad pública, el paso que se debe seguir consiste en adentrarse en el dominio y conocimiento del contexto académico y técnico de los datos el cual, como se muestra en la parte derecha de la figura 3.1, está compuesto por seis niveles: los tipos de datos existentes y disponibles, las disciplinas y tendencias bajo las cuales pueden ser analizados los datos, el grado de profundidad que se puede alcanzar a través de la gestión de estos, el dominio de los métodos y las técnicas que serán empleados en la gestión de los datos, el conocimiento de los fundamentos y las bases teóricas que soportan las técnicas y los métodos seleccionados y, finalmente, la disposición y el dominio de las herramientas requeridas para la gestión de las cifras y los análisis institucionales implementados.
3.2.1 Nivel 2.1. Tipos de datos
El primer nivel del contexto académico y técnico de los datos lo conforman los tipos de datos existentes y disponibles en el escenario de las universidades públicas. ¿Qué tipos de datos existen a nivel institucional?, esta es la primera inquietud que debemos enfrentar en las universidades oficiales al abordar académica y técnicamente el mundo de los datos. En la actualidad, como se ilustra en la figura 3.6 y se expuso de manera detallada en la sección sobre los datos del Capítulo 2, los datos disponibles a nivel mundial e institucional pueden ser clasificados en tres tipologías: estructurados, semiestructurados y no estructurados.
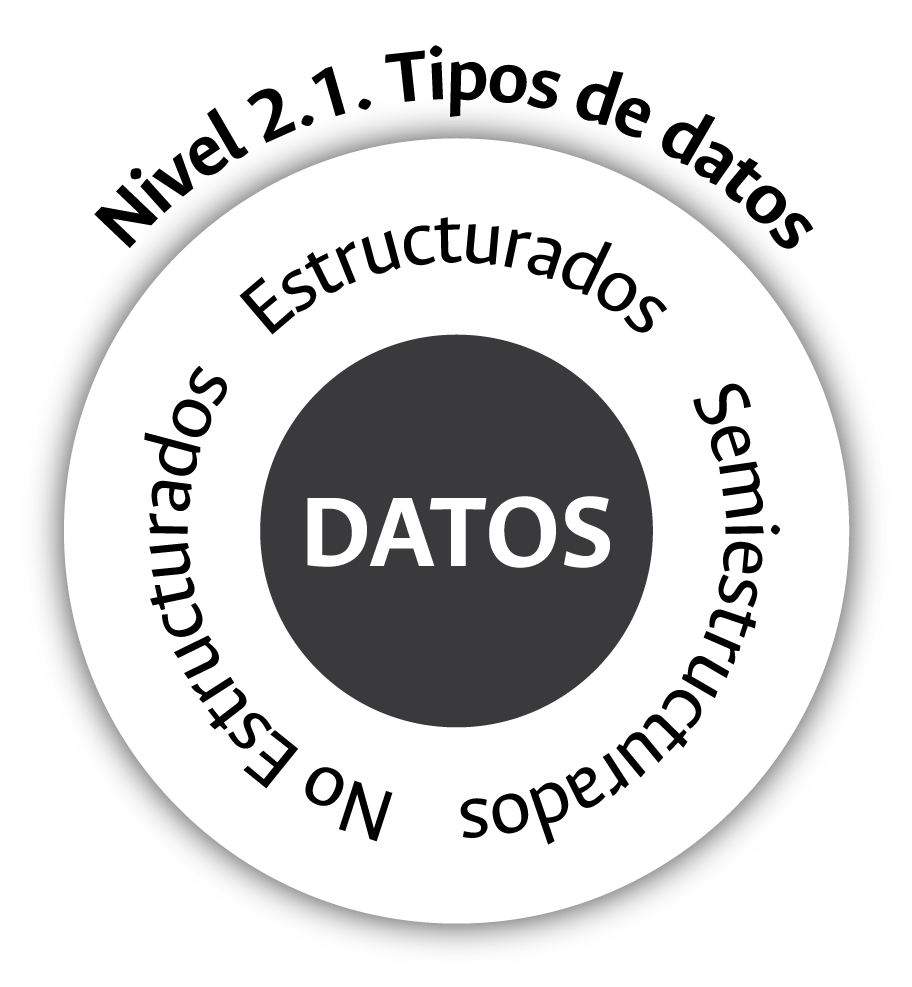
Figura 3.6: Tipos de datos. Fuente: elaboración propia.
Hasta hace no más de 30 años, como se expuso en el capítulo anterior, los principales tipos de datos existentes, estudiados, analizados y gestionables eran aquellos conocidos como estructurados (filas – columnas). Hoy, el mundo de los datos ha evolucionado hacia nuevas tipologías en donde los de naturaleza semiestructurada y no estructurada han adquirido un rol protagónico hasta el punto de convertirse en los más abundantes.
A pesar del crecimiento y auge de los datos de naturaleza semiestructurada y no estructurada en diversos contextos, en el escenario de las universidades, el centro de atención en términos de gestión y demanda de información estadística se concentra actualmente en el mundo de los datos estructurados que se encuentran disponibles en los sistemas de información tradicionales. La universidad contemporánea muy poco ha avanzado en la gestión, el análisis y la disposición de información derivada del uso de datos de tipo semiestructurado o no estructurado.
3.2.2 Nivel 2.2. Disciplinas y tendencias
El segundo nivel del contexto académico y técnico de los datos, como se observa en la figura 3.7, lo conforman las disciplinas y tendencias bajo las cuales es posible acceder a los datos y extraer el conocimiento contenido en estos. ¿Bajo qué disciplina o tendencia serán analizados los datos?, esta es la segunda inquietud que debemos enfrentar en las universidades al abordar académica y técnicamente el mundo del análisis de las cifras y, desde ya, nuestra respuesta a tal inquietud es: aprovechando lo mejor posible el trabajo con dos o más disciplinas, idealmente con el uso de todas.
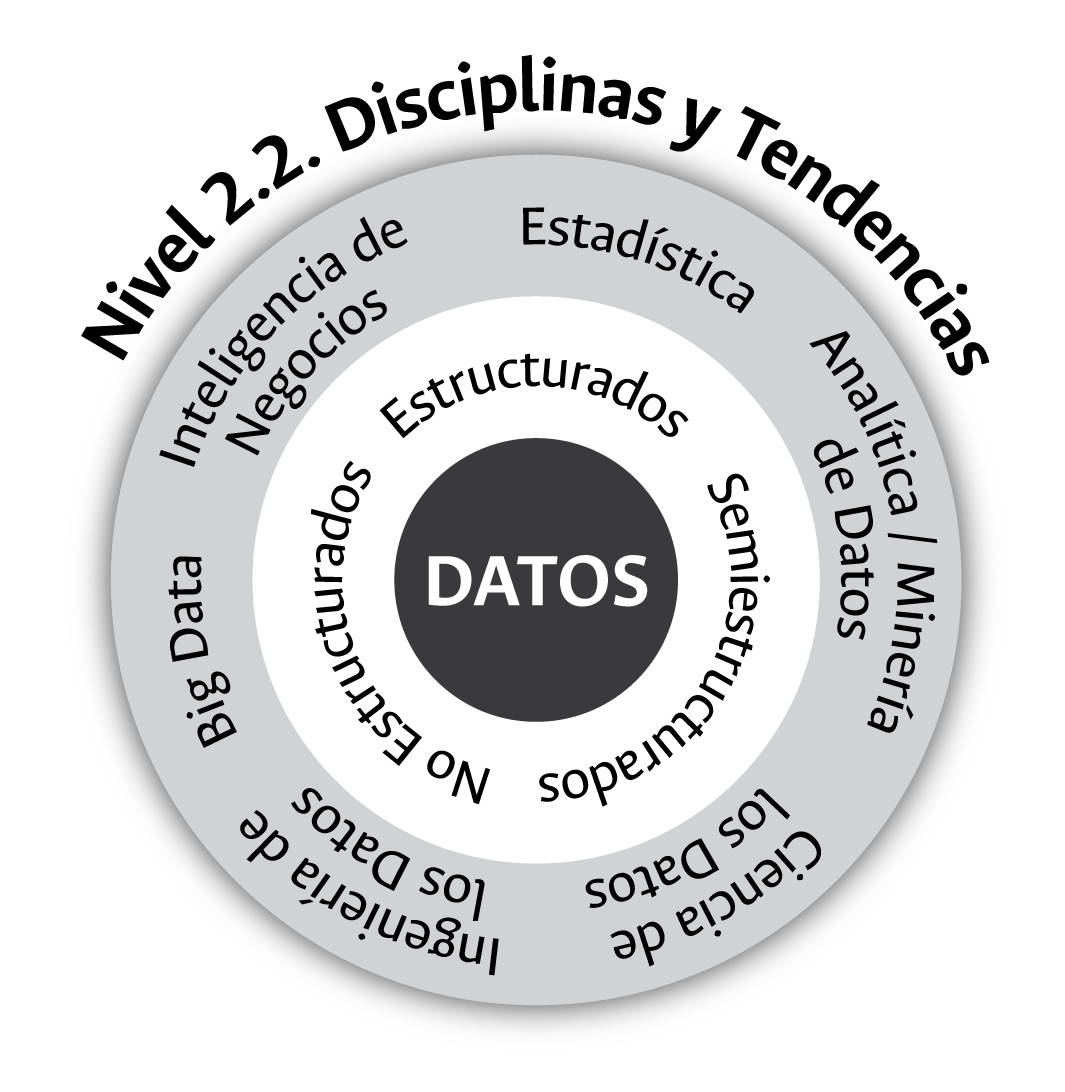
Figura 3.7: Disciplinas y tendencias para el estudio de los datos.
El crecimiento en la variedad de los datos, sumado a los grandes avances tecnológicos alcanzados durante los últimos años, ha llevado –como se mostró a lo largo del Capítulo 2 de este documento– al surgimiento de nuevas tendencias y disciplinas académicas que han encontrado en los datos su objeto de estudio. La estadística, a lo largo de la historia, ha sido la disciplina científica que se ha encargado del estudio de los datos y de acompañar con sus análisis al Estado y sus instituciones. Esta disciplina del conocimiento se encuentra hoy acompañada por nuevas formas de aproximarse a los datos soportadas principalmente en la capacidad que nos ofrecen las TIC y del surgimiento de modelos, marcos o entornos de aproximación a los datos que han mostrado ser útiles en el escenario de las entidades privadas, principalmente. La inteligencia de negocios, la minería o analítica de datos, el Big Data, la ciencia de los datos, y nuevas aproximaciones como el internet de las cosas o el blockchain, nos muestran que al mundo de los datos han llegado nuevos actores que están evidenciando nuevas y variadas formas de extraer el conocimiento existente en estos.
3.2.3 Nivel 2.3. Aproximaciones – Énfasis
El tercer nivel del contexto académico de los datos, como se observa en la figura 3.8, lo conforman las aproximaciones, los énfasis o los propósitos buscados con su gestión. ¿Qué queremos responder y qué uso, en términos de análisis, haremos de los datos disponibles a nivel institucional?, esta es la tercera inquietud que guía una apuesta institucional de gestión de la información cuantitativa a través del entendimiento y la exposición de las posibilidades de análisis hoy existentes en materia estadística.
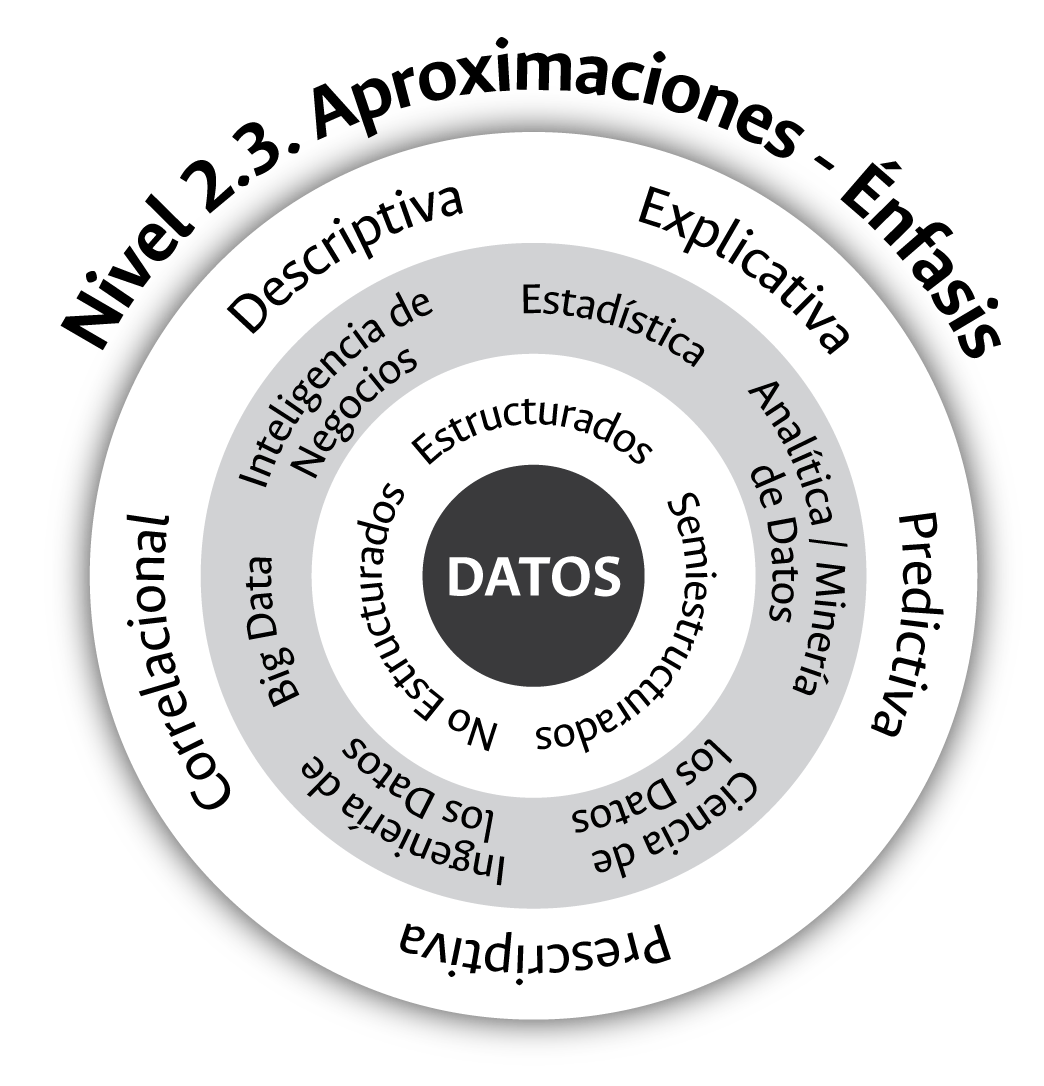
Figura 3.8: Aproximaciones para el estudio de los datos.
El valor de los datos disponibles a nivel institucional, como se muestra en la figura 3.8, no se agota con un único propósito y uso. Estos, a diferencia de muchos de los recursos hoy disponibles a nivel organizacional, pueden ser usados en múltiples ocasiones y con diversos propósitos, dada la mencionada capacidad no rival existente en ellos. En la mayoría de los casos, el interés es de tipo descriptivo: conteos, proporciones, tasas, razones; medidas de tendencia central, de dispersión, de apuntamiento, y visualizaciones o representaciones gráficas, por ejemplo. En otras ocasiones, los datos pueden ser empleados con propósitos que superan el nivel descriptivo y que se ubican en el escenario de lo correlacional. Algunas técnicas de la minería o analítica de datos y de la estadística tienen como fin encontrar agrupaciones y patrones ocultos en los datos, que no son fáciles de detectar a partir de un acercamiento descriptivo a estos.
Los acercamientos descriptivos y correlacionales a partir de los datos nos permiten conocer y acceder a información relacionada con el qué y el cómo de ciertos aspectos de interés institucional. Qué cantidad tenemos, qué características tienen los miembros que conforman una o más poblaciones, cómo y a qué ritmo varían en el tiempo estas características, cómo las representamos y visualizamos, cómo se correlacionan ciertas variables, cómo se agrupan algunos individuos a partir de semejanzas en sus variables, entre otros aspectos, conforman algunos usos de los datos cuyo alcance se ubica en el contexto de lo descriptivo o lo correlacional. No obstante, la curiosidad humana no se conforma con el qué o el cómo observado a partir de los datos disponibles, y se interesa en las razones de lo observado a nivel descriptivo o correlacional. Teorías, preguntas, hipótesis, pruebas, entre otras, se unen alrededor de los mismos datos con el fin de aproximarse a las causas de un problema y adentrarse en el conocimiento y la explicación del porqué o los porqués de dicho problema.
Además del qué, el cómo y el porqué, los mismos datos u otros disponibles a nivel institucional nos permiten aproximarnos a la pregunta de qué podrá o podría pasar en un futuro a partir de lo observado en el pasado y el presente. La predicción, a partir de los datos disponibles, es uno de los usos más deseados y mayormente buscados por el Estado y sus entidades dada la capacidad que esta nos ofrece para direccionar las políticas públicas y maximizar los impactos deseados. La estadística y la analítica o minería de datos ofrecen cientos de técnicas orientadas a la predicción las cuales, además de conocerlas y dominarlas, demandan a nivel institucional la disposición y conservación de la información cuantitativa histórica.
Hoy como nunca antes, las diversas técnicas disponibles en el contexto de las disciplinas o aproximaciones expuestas en la figura 3.8 nos permiten extraer, a partir de un conjunto de datos, múltiples respuestas asociadas a un mismo fenómeno de interés, hecho que nos convoca a realizar análisis de tipo prescriptivo con el objetivo de seleccionar la mejor respuesta entre cientos disponibles.
3.2.4 Nivel 2.4. Métodos y técnicas
El cuarto nivel del contexto académico y técnico de los datos cuantitativos lo conforman los métodos y las técnicas hoy existentes y disponibles para su análisis. ¿Qué método o técnica emplearemos para dar respuesta a las preguntas de interés institucional?, este es el cuarto interrogante que guía una apuesta universitaria de gestión de información cuantitativa y, para responderlo, debemos conocer y dominar diversos métodos existentes para el análisis cuantitativo.
La cantidad de métodos y técnicas hoy existentes asociadas al análisis de los datos, como se observa en la figura 3.9, crece día a día dado el alto interés que ha despertado su estudio en las instituciones, así como la capacidad humana, técnica y académica actualmente disponible que permite una adecuada gestión de los mismos. Los métodos y las técnicas existentes para el análisis de los datos dependen en una buena medida de los propósitos buscados. Si el interés es, por ejemplo, una aproximación o análisis descriptivo, se requiere únicamente la habilidad para contar y resumir el comportamiento de las variables a través de tasas, razones, proporciones, medidas de dispersión, variabilidad, etc. En contraste, si el interés es de naturaleza explicativa, nos acercamos al contexto científico de los datos y allí contamos con técnicas de análisis cuantitativo como el diseño experimental, el muestreo, la epidemiología, el modelamiento a través de regresiones, etc., que nos permite acercarnos desde los datos a la causa de las cosas.
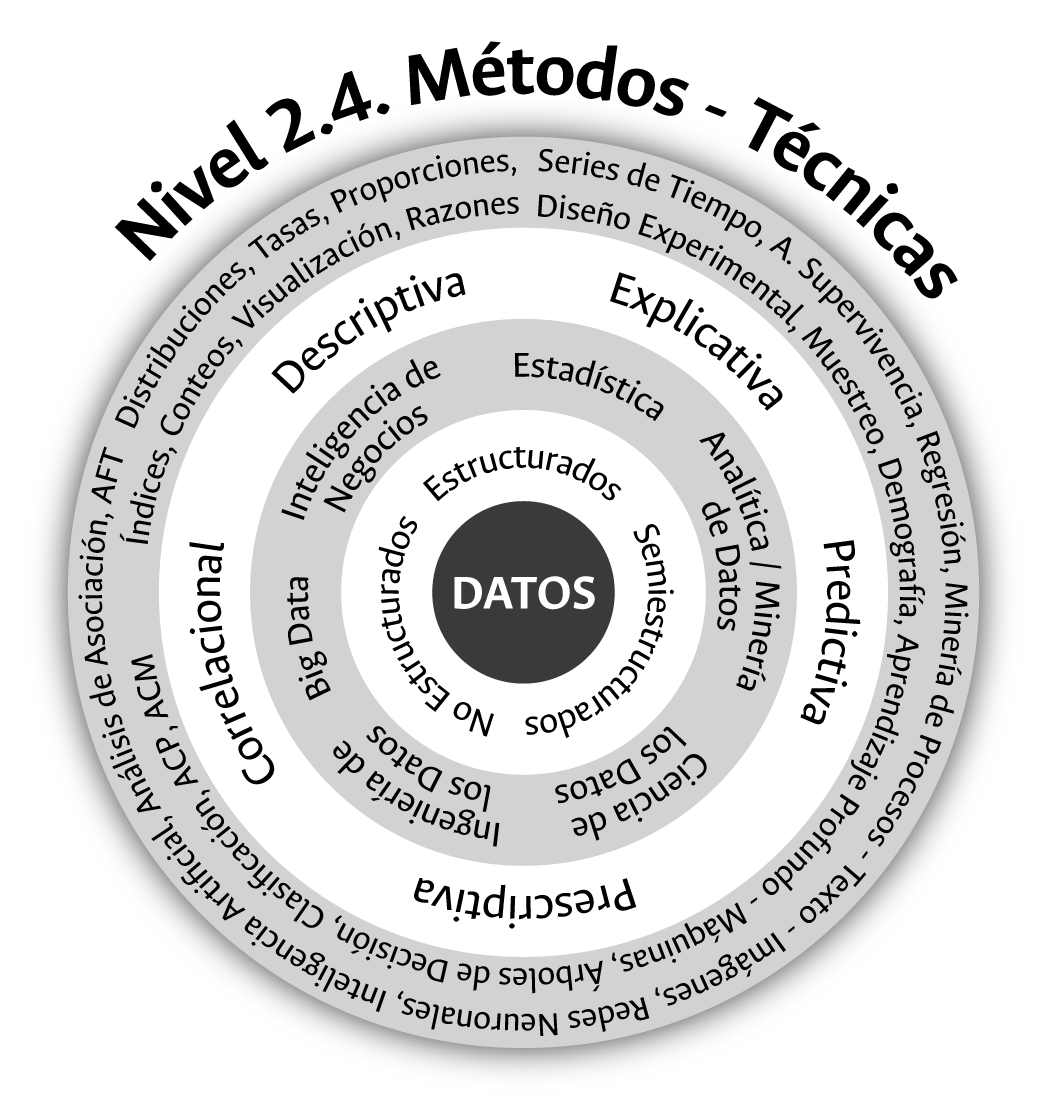
Figura 3.9: Métodos y técnicas para el abordaje de los datos.
Si el interés es de tipo correlacional o predictivo, por ejemplo, surgen con fuerza las técnicas de minería de datos como el análisis de texto, de video y de audios, los árboles de decisión, la inteligencia artificial, el aprendizaje automático, los análisis de asociación, de clasificación, de correspondencias múltiples, de componentes principales, de asociación, etc., a los cuales se suman técnicas de computación paralela o distribuida si los datos bajo análisis superan la capacidad computacional convencional y se ubican en el contexto de los grandes datos o Big Data. Finalmente, ante la presencia de múltiples soluciones sobre un problema determinado derivado de la disposición y el uso de las diversas técnicas existentes para el análisis de los datos, surge la necesidad del uso de técnicas de simulación y optimización con el objetivo de seleccionar aquella respuesta, entre cientos disponibles, que nos permite hacer el mejor uso de los recursos con los que se cuenta a nivel institucional –aproximación prescriptiva–.
3.2.5 Nivel 2.5. Fundamentos – Bases teóricas
El quinto nivel del contexto académico de los datos lo conforman los fundamentos o las bases teóricas que soportan la gran variedad de métodos y técnicas existentes para el abordaje y estudio de estos (figura 3.10). ¿Cuáles fundamentos o bases teóricas soportan los métodos o las técnicas cuantitativas empleadas en la universidad?, este es el quinto interrogante el cual, más que responderse de manera puntual a nivel de las universidades públicas, debemos reconocer que existe y se encuentra como base de muchas de las técnicas cuantitativas que soportan los análisis y las aproximaciones a los datos en la actualidad.
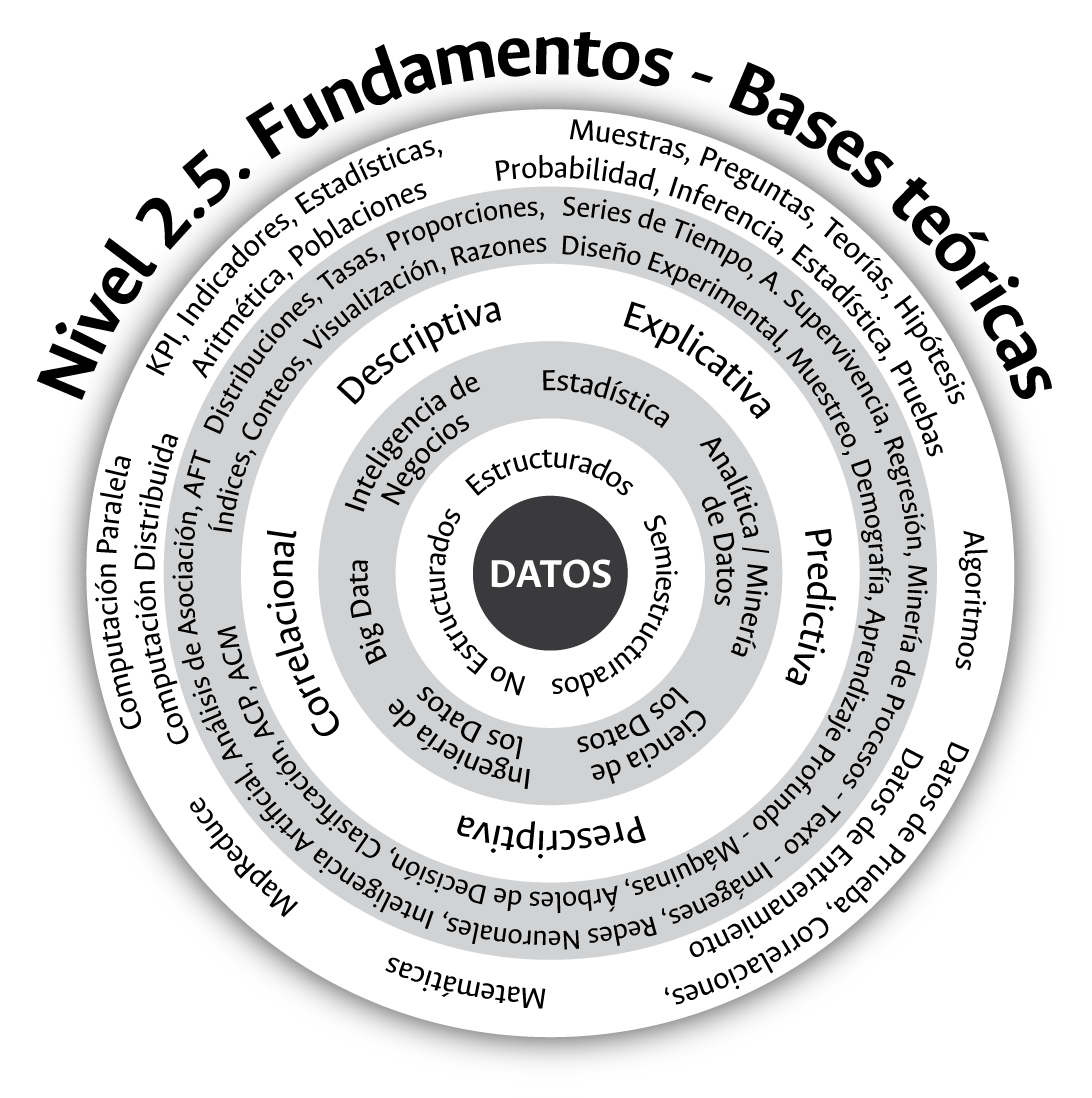
Figura 3.10: Fundamentos y bases teóricas que soportan el estudio de los datos.
Las disciplinas, tendencias, aproximaciones y técnicas asociadas al análisis de los datos se soportan en un número importante de fundamentos conceptuales, los cuales nos permiten conservar el andamiaje y el abanico de posibilidades existentes en el contexto de la gestión de las cifras cuantitativas. La aritmética, que soporta principalmente las aproximaciones descriptivas, conserva aún un lugar preponderante dada su capacidad para extraer conocimiento oportuno y rápido a partir del conteo, la comparación y la representación gráfica –visualización– de la información disponible. Las hipótesis, la inferencia estadística, la probabilidad, la aleatoriedad, las preguntas de investigación, las pruebas estadísticas, entre otras, soportan la línea científica de los datos hoy en manos de la disciplina estadística, a través de la cual es posible aportar al avance en las fronteras del conocimiento.
Los algoritmos, a diferencia de los fundamentos que soportan, por ejemplo, a la estadística, son los protagonistas en el crecimiento que experimentan las técnicas de minería y analítica de datos. Estas secuencias lógicas se han beneficiado de manera significativa del surgimiento y crecimiento de la capacidad de cómputo existente, hecho que les permite llevar a cabo, en poco tiempo, los cientos, miles o millones de pasos requeridos para su implementación. El gran volumen, la variedad y la velocidad con la que se requiere la información en la actualidad ha llevado a la incursión de nuevos paradigmas conceptuales para la gestión de Big Data como, por ejemplo, el entorno MapReduce, consistente en dividir/distribuir un gran problema en miles o millones de pequeños problemas localizados en igual o menor cantidad de nodos computacionales. La aritmética, la inferencia, la probabilidad, los algoritmos, etc., experimentan un enfrentamiento latente en pro de convertirse en el fundamento dominante para aproximarse al mundo contemporáneo de los datos.
3.2.6 Nivel 2.6. Herramientas
El sexto y último nivel del contexto académico y técnico que experimenta el análisis cuantitativo de los datos en la actualidad lo conforma el mundo de las herramientas tecnológicas existentes para la gestión y disposición de las cifras institucionales. ¿Cuáles herramientas tecnológicas se requieren para la gestión de los datos disponibles a nivel institucional?, este es el último interrogante que debemos responder para garantizar el adecuado desarrollo de los procesos institucionales orientados a la gestión de los datos cuantitativos disponibles en una universidad pública. En la actualidad, para la gestión de datos existen herramientas tecnológicas que van, desde el software libre hasta el comercial de bajo y alto costo; las hay desde el espectro empresarial local hasta el multinacional; las hay altamente versátiles y que nos exigen habilidades en programación hasta las poco versátiles o focalizadas en donde no se requieren dichas habilidades, etc. El problema que hoy experimentan las organizaciones públicas y privadas no es la imposibilidad de acceder a una herramienta tecnológica para el análisis de los datos disponibles a nivel institucional sino saber cuál y bajo qué criterios debemos seleccionar dichas herramientas.
Como se observa y se resume en la figura 3.11, los tipos de datos disponibles actualmente son diversos en sus tipologías, las disciplinas y tendencias encargadas de su estudio se han incrementado, los propósitos y potenciales usos han evolucionado, las técnicas disponibles para extraer y generar valor a partir de estos se han multiplicado, y los fundamentos conceptuales detrás de dichas técnicas se han aquilatado y posicionado. Este boom por la conceptualización, el estudio y uso de los datos se ve reflejado en una creciente cantidad de herramientas, en especial de naturaleza tecnológica, disponibles para su gestión. Estas herramientas, que se ilustran de manera general y subestimada en la figura 3.11, existen por cientos, incluso miles, y las hay de naturaleza libre o comercial, cuyo alcance ronda el espectro multinacional.
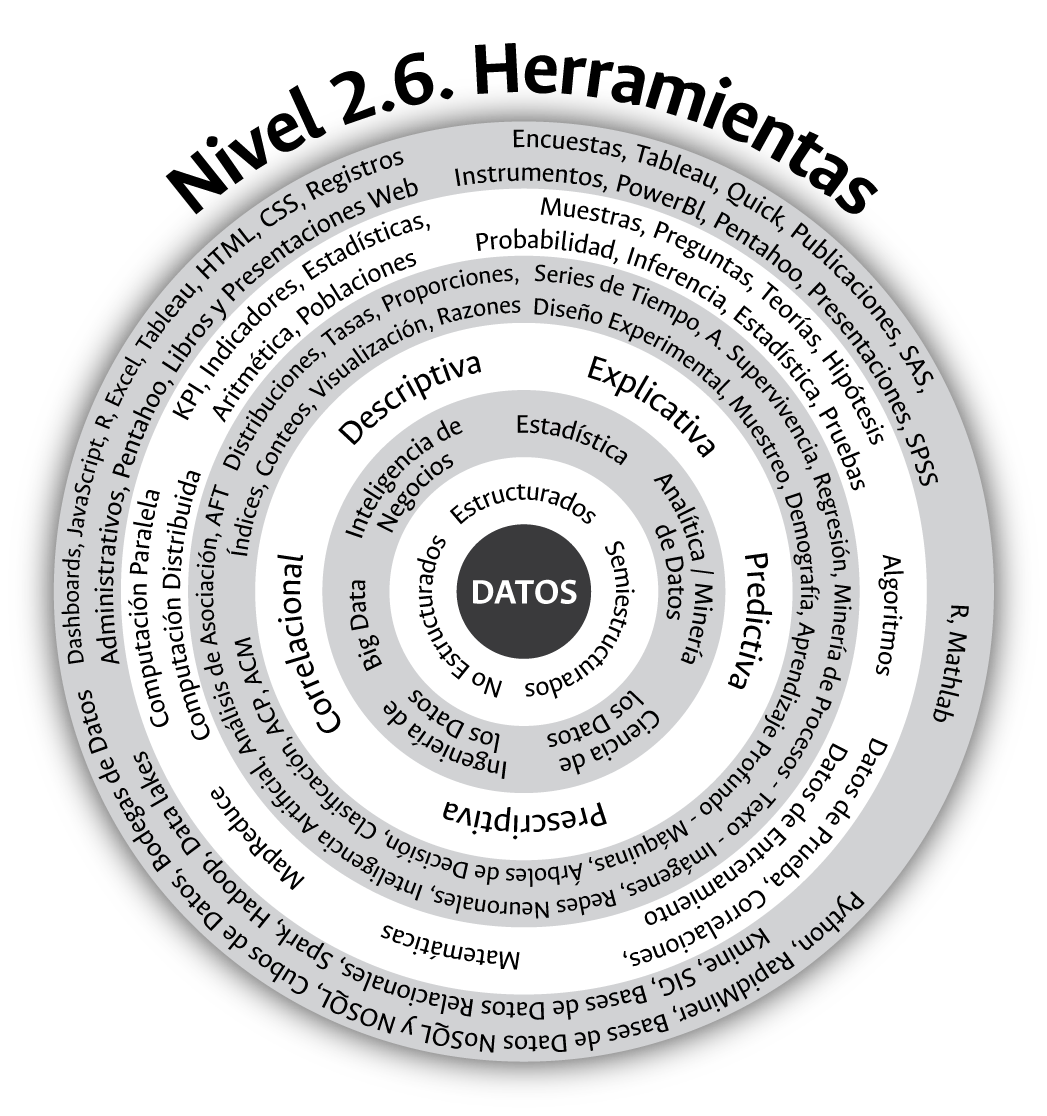
Figura 3.11: Herramientas disponibles para la gestión de los datos.
El mundo de la inteligencia de negocios, por ejemplo, dispone de entornos y herramientas como bodegas de datos, data marts, data cubos, dashboards, Tableau, Pentahoo, PowerBI, Qlick, etc., todos ellos instrumentos y software de tipo tecnológico orientados a la organización y gestión de los datos. En el escenario de la estadística, por ejemplo, disponemos de software como SAS, SPSS, Matlab, R, Excel, entre otros; en el de la minería o analítica de datos, Kmine, RapidMiner, SAS, R, SPSS, etc., y, finalmente, en el mundo del Big Data disponemos de herramientas o soluciones de tipo tecnológico que intervienen en la gestión de este tipo de datos como las bases de datos NoSQL, los lagos de datos Data Lakes y entornos de aplicaciones como Hahoop o Spark, por mencionar algunos casos. Es tal el crecimiento que han experimentado las herramientas tecnológicas disponibles para la gestión de los datos, así como el grado de publicidad y comercialización alcanzado por algunas de estas, que hoy podríamos creer, de manera errónea, que la tecnología es el fin en la gestión de los datos y que su adquisición a nivel estatal e institucional es la solución requerida para la extracción del valor existente en ellos. Sin lugar a dudas, hoy no es concebible y viable una apuesta por la gestión de los datos que no conciba el uso de herramientas de tipo tecnológico; no obstante, como mostraremos en el siguiente capítulo, estas son un medio y no un fin. En el contexto de lo público el fin es la información de interés público cuya disposición exige cumplir un número de pasos –proceso estadístico– dentro de los cuales, desde luego, el uso y la disposición de herramientas de naturaleza tecnológica juega un papel especial.