2.4 Inteligencia de negocios
La inteligencia de negocios (BI por sus siglas en inglés: Business Intelligence), cuya acepción se presume fue acuñada por primera vez en los años noventa del siglo XX por miembros de la empresa Gartner, es considerada como “el conjunto de aplicaciones, infraestructura, herramientas y mejores prácticas que permiten el acceso y análisis de la información para mejorar y optimizar el desempeño de las organizaciones”96. En la figura 2.1 se presenta la arquitectura típica genérica que acompaña un modelo de inteligencia de negocios97 a través del cual, aprovechando las bondades que nos ofrece la tecnología, es posible disponer de información cuantitativa oportuna y de calidad para la toma de decisiones institucionales.
Los datos contenidos en bases de datos de sistemas de información transaccionales internos, datos contenidos en otros registros internos, así como datos disponibles en fuentes externas de información, conforman el primer elemento de un modelo de inteligencia de negocios. Los datos almacenados en las bases de datos asociadas a los sistemas de información SQL o NoSQL, como se ilustra en la figura 2.1, son la fuente central en el modelo. De manera complementaria, en las organizaciones aún existe información interna que no se encuentra almacenada en sus bases de datos o que es de naturaleza externa y no está bajo su gobernabilidad, pero que es de interés por el valor institucional de la misma para la toma de decisiones. Un ejemplo de fuente de información externa de interés de las universidades públicas y privadas en Colombia son los resultados obtenidos por los estudiantes en las competencias genéricas y específicas del Examen de Estado de Calidad de la Educación Superior Saber Pro a cargo del Instituto Colombiano para la Evaluación de la Educación (Icfes).
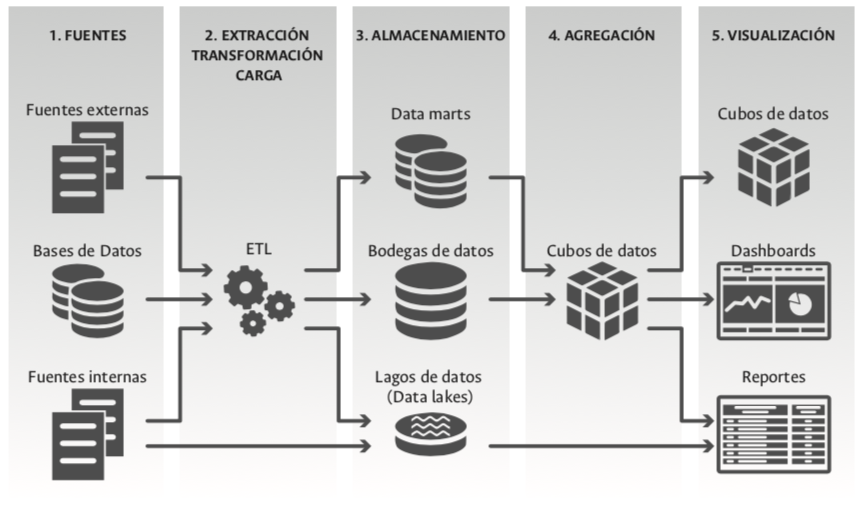
Figura 2.1: Arquitectura tecnológica típica de un modelo de inteligencia de negocios. Adaptación con base en arquitecturas semejantes. Fuente: elaboración propia.
El segundo componente de un modelo de inteligencia de negocios lo conforman las herramientas tecnológicas centradas en la extracción (E), transformación (T) y carga de los datos (L) con propósitos analíticos (ETL). Los datos de interés que se encuentran disponibles en las bases de datos de los sistemas de información y en otras fuentes internas y externas deben ser extraídos y luego transformados, de acuerdo con las necesidades que se tengan en términos de información institucional para finalmente ser cargados en un lugar especial para su posterior uso. Los procesos ETL se enfrentan a una realidad que presenta una buena parte de los sistemas de información institucional y que llevan al fracaso de una gran proporción de este tipo de iniciativas, como son: desconocimiento de la arquitectura de las bases de datos institucionales98, duplicidad de acciones semejantes en diferentes sistemas, tecnologías distintas, una alta cantidad de sistemas de información, bajos niveles de interoperabilidad entre los sistemas, poca calidad de los datos almacenados, ausencia de codificaciones y bajo uso de estándares institucionales, nacionales e internacionales, entre otros criterios. Si estos aspectos no son analizados y resueltos pueden impedir el desarrollo de un proyecto de inteligencia de negocios a nivel institucional.
Los datos que son extraídos (E) de las bases de datos u otras fuen- tes de interés institucional y luego son trasformados (T) con propósitos analíticos son almacenados, en una apuesta tradicional de BI, en bases de datos conocidas como bodegas de datos (Data Warehouse DW), Data Marts DM o Data Lakes99; estos conforman el tercer elemento en una arquitectura y apuesta de BI (figura 2.1) y son quizá el corazón de este tipo de iniciativas, pues es allí donde se encuentra almacenada la información requerida para los análisis y la toma de decisiones institucionales.
Según Gartner, “una bodega de datos100 es una arquitectura de almacenamiento de información diseñada para mantener datos extraídos de sistemas transaccionales, bodegas de datos operacionales y fuentes externas”101. Así mismo, según Oracle, “una bodega de datos es una base de datos diseñada para permitir las actividades de inteligencia de negocios: existe para ayudar a los usuarios a comprender y mejorar el rendimiento de la organización102. Las bodegas de datos están orientadas principalmente al almacenamiento, la consulta y el análisis de datos históricos provenientes de bases de datos relacionales y se valen, para ello, de una arquitectura e infraestructura especial103. Aunque existen diversas propuestas de arquitectura para las bodegas de datos y en sí para una apuesta de BI104, el debate en general se centra en dos paradigmas: la arquitectura propuesta por Kimball, Ralph y Ross, Margy (2013) y la propuesta por Inmon (2005).
El cuarto y el quinto de los componentes de una arquitectura típica de una apuesta de inteligencia de negocios BI lo conforman las herramientas y aplicaciones tecnológicas encargadas de suministrar las cifras de interés institucional a los usuarios e interesados finales. Estos componentes, que se ilustran gráficamente en las partes 4 y 5 de la figura 2.1, agrupan un número importante de aplicaciones entre las que se destacan los datacubos, los reportes y los cuadros de mando, tableros o dashboards.
En primer lugar, los datacubos, cubos de datos o cubos de información son una estrategia tecnológica empleada para dos propósitos principales: como mecanismo previo para la disposición y visualización de las cifras requeridas a nivel institucional (componente 4 de la figura 2.1) o con el objetivo de que el usuario final interactúe, de manera tabular y en línea, con el fin de construir, reconstruir y extraer, desde múltiples perspectivas/dimensiones, información de interés particular contenida en los Data Marts y en las bodegas de datos. En un sentido general, un cubo de datos es equivalente a las funciones que cumple una tabla dinámica en Excel, con la diferencia de que esta se encuentra disponible en línea.
En segundo lugar, los reportes son una estrategia empleada para suministrar tecnológicamente información tabular que contiene cifras de interés institucional, de alta utilidad para aquellas organizaciones o entidades que requieren suministrar informes o microdatos de manera periódica a actores internos o externos.
En tercer lugar, los tableros de mando o dashboards conforman la apuesta gráfica para el seguimiento y la presentación de las cifras, principalmente de naturaleza descriptiva, de una organización y son, de lejos, el mecanismo tecnológico más empleado para gestionar la información cuantitativa institucional en una organización guiada por una apuesta de inteligencia de negocios.
Aunque los dashboards pueden ser empleados en una entidad para presentar información de manera gráfica y tabular proveniente de datos de cualquier naturaleza y complejidad, desde sus orígenes han sido ampliamente empleados para representar información gráfica de tipo descriptivo y derivada de fuentes estructuradas o, a lo sumo, semiestructuradas. Conteos, tortas, diagramas de barras, histogramas, diagramas de caja (box plots), mapas, diagramas de líneas, gráficos de dispersión, barras de progreso, velocímetros, etc., conforman, con una alta frecuencia, la estructura de los objetos gráficos105 de un dashboard tradicional. Este tipo de instrumentos, que alcanzaron una alta popularidad especialmente en el sector privado a finales del siglo pasado e inicios del actual, es la estrategia que más se utiliza en la actualidad por las entidades que están incursionando de manera decidida en la gestión de la información cuantitativa institucional y consideran la tecnología como su aliado para este propósito.
El diseño y la construcción de dashboards o de otra estrategia institucional a través de la cual se suministra información cuantitativa de manera tabular y gráfica que permita apoyar la toma de decisiones institucionales y rendir cuentas a la sociedad a través de la apertura de sus cifras (transparencia) implica, a su vez, el dominio, el conocimiento y la disposición principalmente de dos elementos centrales y constitutivos de las mismas: la construcción de gráficos y la disposición, acceso y dominio de herramientas tecnológicas modernas para su visualización106.
Aunque se cree que la construcción y representación gráfica de cifras cuantitativas es sencilla y relativamente moderna, esta tiene raíces históricas profundas construidas durante siglos de historia en donde consideraciones psicológicas, sociológicas, artísticas, estéticas, estadísticas y recientemente computacionales han jugado un rol central en su diseño, construcción y disposición. Estos requisitos, muy pocas veces conocidos y dominados en el contexto de la construcción de gráficos almacenados en dashboards institucionales son fundamentales en el mensaje que pretende ser llevado y, en muchos casos, son una de las piezas centrales de abuso y desinformación de aquello que pretende ser contado a través de una representación gráfica107.
Finalmente, la disposición de gráficos para representar cifras institucionales es una actividad que ha adquirido un alto interés y desarrollo desde una perspectiva tecnológica durante los últimos años. Del boletín estadístico, cuyos objetos gráficos en un principio eran diseñados y construidos por dibujantes, hemos pasado a disponer de un sinnúmero de herramientas tecnológicas de uso comercial o libre en donde el estadistico, ingeniero, diseñador, técnico u otro experto con habilidades para el dominio de este tipo de herramientas son los encargados de su construcción y visualización.
Aunque actualmente existen cientos de herramientas tecnológicas de alcance comercial o libre para la construcción y visualización de gráficos que permitan representar cifras institucionales108, en el contexto de la inteligencia de negocios sobresalen software para tal propósito como Tableau, PowerBI, OBIEE, Qlik, Pentaho, SAS, IBM, SAP, R, Phyton, principalmente. En otras palabras, en el escenario de la inteligencia de negocios o de cualquier otra estrategia emprendida por las instituciones para representar y entregar información cuantitativa institucional a través del uso de TIC, el problema no es la ausencia de herramientas sino la abundancia de las mismas, así como el dominio y la capacidad institucional de selección de las que mejor convengan.
El Big Data, la analítica o minería de datos y la inteligencia de negocios, como acabamos de presentar, tienen dos denominadores comunes: son herramientas o fenómenos que han surgido y se han desarrollado durante los últimos años y se valen de manera intensiva para su desarrollo del dominio y acceso a las TIC. No obstante, la analítica de datos apunta a la extracción de conocimiento oculto existente en datos y expresable a través de patrones extrapolables a escenarios futuros (enfoque predictivo); del Big Data, a la extracción de conocimiento útil contenido en grandes volúmenes de datos, con diversas estructuras y a una gran velocidad y, finalmente, la inteligencia de negocios, a la disposición de una arquitectura tecnológica útil para la extracción y presentación regular de la información contenida en los datos disponibles en una entidad. Estas tres tendencias contemporáneas de abordaje y estudio de los datos son hijas del avance de las TIC, pero el fin buscado con su implementación se ha conservado desde el surgimiento de los Estados modernos: conocimiento para comprender la realidad y tomar las mejores decisiones. Estas nuevas formas de aproximación y estudio de los datos han llegado para acompañar el uso de las técnicas tradicionales de análisis estadístico y enriquecer, con nuevos recursos y aproximaciones, el estudio y la extracción del conocimiento contenido en los datos disponibles a nivel institucional.
Referencias
Inmon, William H. 2005. Building the Data Warehouse. John Wiley & Sons.
Kimball, Ralph y Ross, Margy. 2013. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. John Wiley & Sons.
Ver blog, en http://blogs.gartner.com/it-glossary/business-intelligence-bi/↩
Dado el propósito del presente documento, son muchos los aspectos particulares asociados a la inteligencia de negocios que no se incluyen en este trabajo.↩
A esta realidad se enfrenta cualquier apuesta institucional interesada en extraer cifras oficiales para la toma de decisiones, independientemente de si el proceso se lleva a cabo mediante una apuesta de BI o mediante otra iniciativa. No en vano, como menciona (Wickham 2014), alrededor de un 80% del proceso de extracción de con cimiento a través de datos se dedica a actividades de limpieza y ajuste de los datos requeridos.↩
Los Data Marts y las bodegas de datos son instrumentos tecnológicos empleados para el almacenamiento de datos provenientes de bases de datos que contienen información estructurada, mientras que los Data Lakes o lagos de datos son empleados para el acopio de datos carentes de estructura o no estructurados, principalmente.↩
Aunque en la figura 2.1 se presentan los Data Marts, las bodegas de datos DW y los Data Lakes como herramientas tecnológicas distintas, todas en sí son bodegas de datos dada su orientación hacia el almacenamiento de información obtenida a través de los datos disponibles en los sistemas de información transaccionales, principalmente. Los Data Marts están orientados a almacenar información proveniente de datos estructurados de un único tema o sector dentro de una organización, las DW a almacenar información estructurada proveniente de todos los temas o sectores de una organización, y los Data Lakes a almacenar la información proveniente de datos no estructurados o semiestructurados.↩
Ver IT Glossary, en https://www.gartner.com/it-glossary/data-warehouse↩
Ver Database Data Warehousing Guide, en https://docs.oracle.com/database/121/DWHSG/concept.htm#DWHSG001↩
Las bases de datos relacionales están soportadas en una arquitectura que permite ejecutar un número elevado de operaciones o transacciones que a diario se realizan en una organización (contrataciones, compras, pagos, etc.). En contraste, las bodegas de datos están soportadas en una arquitectura orientada al almacenamiento y la disposición de los datos requeridos para el análisis y la toma de decisiones institucionales. Estas dos arquitecturas distan de manera significativa, hecho que exige ser diseñadas, construidas y administradas de manera diferencial↩
Cuando una apuesta de BI se concentra en un tema área de una entidad, el mecanismo de almacenamiento de los datos no se llama bodega de datos sino Data Mart. En otras palabras, un Data Mart es una base de datos orientada a almacenar la información de un tema puntual o área dentro de una organización como, por ejemplo, para el caso de una universidad, los datos académicos, de investigación o financieros.↩
En el sitio web http://visualizationuniverse.com/ se presenta una propuesta con un inventario de los tipos de gráficos hoy disponibles para la representación gráfica de datos así como otros recursos asociados a la visualización de datos.↩
En el ámbito de lo público, y en especial en el contexto de la transparencia institucional, como veremos más adelante, existe un tercer elemento central que es el de los metadatos o descripción del lenguaje que acompañan las cifras institucionales para que estas sean comprendidas y usadas de la manera correcta por los usuarios de la información expuesta.↩
Entre los trabajos destacados en esta dirección resaltamos los de Friendly et al. (2008); Tufte and Graves-Morris (1997); Chambers (2017); Cleveland, William S y Cleveland, William S (1985), y Wilkinson (1999), los cuales invitamos a explorar y estudiar.↩
En el sitio web https://keshif.me/demo/VisTools#515 se presenta un inventario con más de 400 herramientas tecnológicas muchas de las cuales pueden ser usadas en una apuesta de BI a nivel institucional.↩