library(readr)
Base_prueba_aspirantes <- read_csv(file="datos/Base_prueba_aspirantes.txt")
class(Base_prueba_aspirantes)[1] "spec_tbl_df" "tbl_df" "tbl" "data.frame" Para manipular datos en R, se puede optar por el paquete base o utilizar paquetes adicionales que requieren instalación. Uno de los más populares y versátiles es dplyr. Por ello, a continuación se presentan dos alternativas para realizar manipulaciones de datos según las necesidades: el paquete base de R y dplyr, el cual se instala mediante el comando install.packages("dplyr").
Es importante mencionar que, aunque aquí se muestran dos enfoques, R ofrece múltiples maneras de obtener el mismo resultado. Por lo tanto, estas no son las únicas opciones disponibles. Antes de comenzar, se recomienda disponer de la tabla de datos almacenada como un data frame o un objeto tibble. A continuación, se describen algunas de las tareas más comunes y cómo llevarlas a cabo.
library(readr)
Base_prueba_aspirantes <- read_csv(file="datos/Base_prueba_aspirantes.txt")
class(Base_prueba_aspirantes)[1] "spec_tbl_df" "tbl_df" "tbl" "data.frame" Para esto se emplean los comandos length() y dim() dependiendo el tipo de objeto. El resultado es un vector cuyo primer componente indica número de filas, el segundo número de columnas, y así sucesivamente para más dimensiones.
# En vectores y listas
vector <- c(1, 2, 3, 4)
length(vector)[1] 4lista <- list(nombre = "Juan", edad = 25, notas = c(8, 9, 10))
length(lista)[1] 3# En matrices, arreglos y data frames
matriz <- matrix(1:8, nrow = 2, ncol = 4)
dim(matriz)[1] 2 4arreglo <- array(1:8, dim = c(2, 2, 2))
dim(arreglo)[1] 2 2 2dim(Base_prueba_aspirantes)[1] 5000 59Para mostrar los nombres de todas las columnas del data frame se emplea el comando names(Base_prueba_aspirantes). La selección se realiza simplemente indicando el nombre de las columnas o los números correspondientes a los índices en el orden deseado.
Base_select <- Base_prueba_aspirantes[,c("ID","YEAR","SEMESTRE","SEXO","FACULTAD","PTOTAL")] # base
Base_select <- Base_prueba_aspirantes[,c(1,3,4,22,38,34)] # base
library(dplyr) # solo es necesario la primera vez
Base_select <- Base_prueba_aspirantes %>% select(ID,YEAR,SEMESTRE,SEXO,FACULTAD,PTOTAL) # dplyr
Base_select <- Base_prueba_aspirantes %>% select(1,3,4,22,38,34) # dplyr
datatable(Base_select)A continuación se presenta cómo seleccionar columnas que cumplen con ciertas características especificadas mediante el paquete tidyselect, y en algunos casos con el paquete base de R.
Base_prueba_aspirantes %>% select(starts_with("COD")) %>% datatable()# con el paquete base:
# Base_prueba_aspirantes[ , grep("^COD", names(Base_prueba_aspirantes))]Base_prueba_aspirantes %>% select(ends_with("RES")) %>% datatable()# con el paquete base:
# Base_prueba_aspirantes[ , grep("RES$", names(Base_prueba_aspirantes))]Base_prueba_aspirantes %>% select(contains("DEP")) %>% datatable()# con el paquete base:
# Base_prueba_aspirantes[ , grep("DEP", names(Base_prueba_aspirantes))]matches(): Selecciona columnas cuyos nombres coinciden con una expresión regular. Es útil para patrones más complejos. Por ejemplo, matches(“^X[0-9]+$”) selecciona todas las columnas que comienzan con “X” seguidas de números.
everything(): Selecciona todas las columnas en el data frame. Puede usarse en combinación con otros selectores para reordenar las columnas. Por ejemplo, select(df, starts_with(“col”), everything()) selecciona las columnas que comienzan con “col” y luego todas las demás.
num_range(): Selecciona columnas con nombres que siguen un patrón numérico. Es útil para columnas que se nombran con un prefijo seguido de números. Por ejemplo, num_range(“X”, 1:5) selecciona X1, X2, X3, X4, y X5.
one_of(): Permite seleccionar columnas cuyos nombres están en un vector. Por ejemplo, one_of(c(“col1”, “col2”)) selecciona las columnas “col1” y “col2”.
all_of(): Similar a one_of(), pero asegura que todas las columnas especificadas estén presentes. Si alguna columna no existe, genera un error.
any_of(): Similar a one_of(), pero no genera un error si alguna de las columnas no existe. Selecciona las columnas que están en el vector, si existen.
drop(): Permite excluir ciertas columnas de la selección. Por ejemplo, select(df, -drop(col1)) elimina la columna col1 del data frame. Análogamente, con el paquete base de R: Base_prueba_aspirantes[ , !names(df) %in% "col1"].
colnames(Base_select)[colnames(Base_select) == "YEAR"] <- "ANNO" # baseBase_select <- Base_select %>% rename(ANNO = YEAR) #dplyr
datatable(Base_select)Existen diversas maneras de ordenar las columnas, a continuación se presentan las más usadas.
# Poner una columna al principio
Base_ordenada <- Base_select[, c("SEXO", setdiff(names(Base_select), "SEXO"))] # base
Base_ordenada <- Base_select %>% relocate(SEXO) # dplyr
datatable(Base_ordenada)# Poner una columna antes que otra
Base_ordenada <- Base_select %>% relocate(SEXO, .before = SEMESTRE) # dplyr
datatable(Base_ordenada)# Poner una columna despues de otra
Base_ordenada <- Base_select %>% relocate(SEXO, .after = FACULTAD) # dplyr
datatable(Base_ordenada)# Poner una columna al final
Base_ordenada <- Base_select[, c(setdiff(names(Base_select), "ID"), "ID")] # base
Base_ordenada <- Base_select %>% relocate(ID, .after = last_col()) # dplyr
datatable(Base_ordenada)# Poner las columnas tipo numerico despues de las columnas tipo caracter
Base_ordenada <- Base_select[, order(sapply(Base_select, is.numeric))] # base
# order ordena los índices basándose en el vector lógico que devuelve sapply, colocando FALSE (carácter) antes que TRUE (numérico).
Base_ordenada <- Base_select %>% relocate(where(is.numeric), .after = where(is.character)) # dplyr
datatable(Base_ordenada)# Especificar un nuevo orden
Base_ordenada <- Base_select[,c("ID","FACULTAD","ANNO","SEMESTRE","SEXO","PTOTAL","FACULTAD")] # base
Base_ordenada <- Base_select %>% select(ID,FACULTAD,ANNO,SEMESTRE,SEXO,PTOTAL,FACULTAD) # dplyr
datatable(Base_ordenada)Por ejemplo, suponiendo que se desea construir la variable PERIODO a partir del año y el semestre. En este caso, se concatenan para formar una variable de tipo caracter por lo tanto se emplea la función paste().
Base_select$PERIODO <- paste(Base_select$ANNO,"-",Base_select$SEMESTRE) # base
Base_select <- Base_select %>% mutate(PERIODO = paste(ANNO,"-",SEMESTRE)) # dplyr
datatable(Base_select)
También se pueden definir nuevas variables a partir de operaciones numéricas o lógicas. Por ejemplo, crear una variable con los puntajes estandarizados se hace de la siguiente manera.
Base_select$PTOTAL_ESTANDAR <- round((Base_select$PTOTAL - mean(Base_select$PTOTAL, na.rm = T)) / sd(Base_select$PTOTAL, na.rm = T),3) # base
# el argumento na.rm permite omitir NA y la función round() redondea al número de cifras decimales especificado
Base_select <- Base_select %>% mutate(PTOTAL_ESTANDAR = round((PTOTAL - mean(PTOTAL, na.rm = T)) / sd(PTOTAL, na.rm = T),3)) # dplyr
datatable(Base_select)
Y para crear una variable dummy que indique si el puntaje fue superior a 600:
Base_select$PTOTAL_ALTO <- ifelse(Base_select$PTOTAL > 600, 1, 0) # base
Base_select <- Base_select %>% mutate(PTOTAL_ATO = ifelse(PTOTAL > 600, 1, 0)) # dplyr
datatable(Base_select)Las filas se pueden realizar filtros sobre una o múltiples variables, empleando operadores lógicos y relacionales.
# Filtrar filas con año mayor a 2021 y de sexo femenino
Base_filtrada <- Base_select[(Base_select$ANNO > 2021 & Base_select$SEXO == "Mujeres"), ] # base
Base_filtrada <- Base_select %>% filter(ANNO > 2021, SEXO == "Mujeres") # dplyr
datatable(Base_filtrada)Las filas se pueden ordenar por una o múltiples variables. Cuando las variables son caracteres, se ordenan en orden alfabéticos y si son factores, deacuerdo a los niveles que se hayan definido.
# Ordenar por año en orden ascendente
Base_select <- Base_select[order(Base_select$ANNO, Base_select$SEMESTRE), ] # base
Base_select <- Base_select %>% arrange(ANNO, SEMESTRE) # dplyr
datatable(Base_select)# Ordenar por año en orden descendente
Base_select <- Base_select[order(-Base_select$ANNO), ] # base
Base_select <- Base_select %>% arrange(desc(ANNO)) # dplyr
datatable(Base_select)Las filas se pueden ordenar por una o múltiples variables y de esta manera aplicar funciones sobre los grupos formados, ya sea funciones de algún paquete o definidas por el usuario. La utilidad de agrupar filas se ve reflejada justamente al aplicar alguna función o transformación sobre los grupos formados.
Base_agrupada <- aggregate(PTOTAL ~ FACULTAD, data = Base_select, FUN = mean) # base
Base_agrupada <- Base_select %>% group_by(FACULTAD) %>% summarise(PROMEDIO = round(mean(PTOTAL, na.rm = TRUE),3)) # dplyr
datatable(Base_agrupada)En ocasiones se desea calcular estadísticas de resumen por columna para tener una idea del compartamiento de los datos.
summary(Base_select) # base ID ANNO SEMESTRE SEXO
Min. :2.100e+01 Min. :2008 Min. :1.000 Length:5000
1st Qu.:1.055e+04 1st Qu.:2012 1st Qu.:1.000 Class :character
Median :2.622e+04 Median :2016 Median :1.000 Mode :character
Mean :1.008e+08 Mean :2016 Mean :1.356
3rd Qu.:4.576e+04 3rd Qu.:2019 3rd Qu.:2.000
Max. :1.234e+09 Max. :2024 Max. :2.000
FACULTAD PTOTAL PERIODO PTOTAL_ESTANDAR
Length:5000 Min. :-27.13 Length:5000 Min. :-2.575
Class :character 1st Qu.:397.34 Class :character 1st Qu.:-0.255
Mode :character Median :483.47 Mode :character Median : 0.216
Mean :444.01 Mean : 0.000
3rd Qu.:554.88 3rd Qu.: 0.606
Max. :929.63 Max. : 2.654
NA's :226 NA's :226
PTOTAL_ALTO PTOTAL_ATO
Min. :0.0000 Min. :0.0000
1st Qu.:0.0000 1st Qu.:0.0000
Median :0.0000 Median :0.0000
Mean :0.1408 Mean :0.1408
3rd Qu.:0.0000 3rd Qu.:0.0000
Max. :1.0000 Max. :1.0000
NA's :226 NA's :226 resumen <- Base_select %>% # dplyr
select(PTOTAL) %>%
summarise(across(where(is.numeric), list(
Media = ~round(mean(.x, na.rm = TRUE),2),
Mediana = ~round(median(.x, na.rm = TRUE),2),
Min = ~round(min(.x, na.rm = TRUE),2),
Max = ~round(max(.x, na.rm = TRUE),2),
SD = ~round(sd(.x, na.rm = TRUE),2))))
datatable(resumen)Algunas funciones útiles son:
| Categoría | Funciones |
|---|---|
| Centralidad | mean(), median() |
| Dispersión | sd(), IQR(), mad() |
| Rango | min(), max() |
| Posición | first(), last(), nth() |
| Conteo | n(), n_distinct() |
| Lógico | any(), all() |
Es útil cuando se dispone de una matriz de datos con filas repetidas y se desea conservar los casos únicos.
Base_unique <- unique(Base_select) # base
Base_unique <- Base_select %>% distinct() # dplyr
datatable(Base_unique)Se pueden eliminar las filas que contengan datos faltantes en al menos una de las columnas o en alguna columna en particular.
# Eliminar las filas con al menos un NA
Base_sinNA <- Base_select[complete.cases(Base_select), ] # base
Base_sinNA <- Base_select %>% na.omit() # dplyr
datatable(Base_sinNA)# Eliminar las filas con NA en una columna particular
Base_sinNA_PTOTAL <- Base_select[!is.na(Base_select$PTOTAL), ] # base
Base_sinNA_PTOTAL <- Base_select %>% filter(!is.na(PTOTAL)) # dplyr
datatable(Base_sinNA_PTOTAL)La familia apply en R es un conjunto de funciones que permiten realizar operaciones eficientes sobre estructuras de datos como vectores, matrices, listas y data frames, evitando el uso de bucles explícitos. Estas funciones son ideales para aplicar operaciones de manera vectorizada y mejorar el rendimiento del código.
| Función | Entrada | Salida | Uso Principal |
|---|---|---|---|
apply |
Matriz | Vector/Matriz | Operar sobre filas o columnas |
lapply |
Lista o vector | Lista | Operar sobre cada elemento |
sapply |
Lista o vector | Vector/Matriz | Similar a lapply pero simplificando |
vapply |
Lista o vector | Vector (tipo definido) | Versión segura de sapply |
tapply |
Vector y factores | Vector/Lista | Operar sobre grupos definidos por factores |
mapply |
Varias listas/vectores | Lista/Vector | Aplicar funciones de manera paralela |
matriz <- matrix(1:9, nrow = 3)
apply(matriz, MARGIN = 1, FUN = sum) # Suma por filas[1] 12 15 18apply(matriz, MARGIN = 2, FUN = sum) # Suma por columnas[1] 6 15 24lista <- list(a = 1:5, b = 6:10)
lapply(lista, mean) # Calcula la media de cada elemento$a
[1] 3
$b
[1] 8lista <- list(a = 1:5, b = 6:10)
sapply(lista, sum) # Calcula la suma de cada elemento y devuelve un vector a b
15 40 lista <- list(a = 1:5, b = 6:10)
vapply(lista, sum, numeric(1)) # Calcula la suma de cada elemento con un tipo de salida definido a b
15 40 valores <- c(1, 2, 3, 4, 5, 6)
grupo <- factor(c("A", "B", "A", "B", "A", "B"))
tapply(valores, grupo, mean) # Calcula la media por grupoA B
3 4 mapply(sum, 1:5, 6:10) # Suma paralela de dos vectores[1] 7 9 11 13 15Es posible cambiar la estructura en la que se presenta la tabla de datos usando la función reshape del paquete base de R o las funciones pivot_wide y pivot_longer del paquete tidyr. La siguiente imagen ilustra el cambio y se muestra el ejemplo con la tabla longitudinal_data.
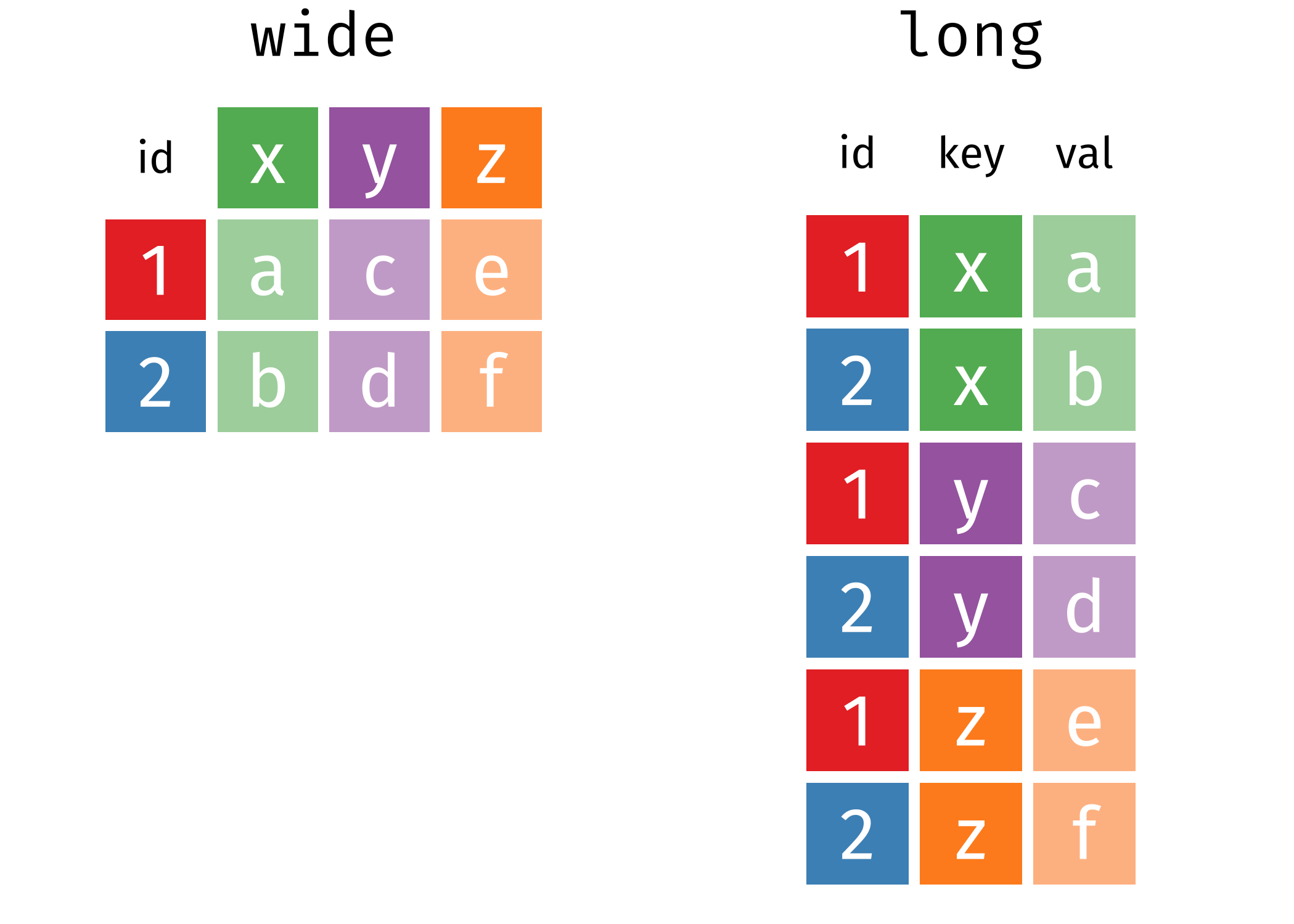
library(tidyr)
# Convertir a formato ancho
formato_ancho <- reshape( # base
longitudinal_data, # Datos
timevar = "VISITA", # Columna a pivotar
idvar = c("ID"), # Columnas que identifican cada fila única
direction = "wide") # Cambiar de largo a ancho
names(formato_ancho) <- gsub("GLUCOSA\\.", "VISITA ", names(formato_ancho)) # Nombres de las nuevas columnas
formato_ancho <- longitudinal_data %>% # tidyr
pivot_wider(
names_from = VISITA, # Columna a pivotar
names_prefix = "VISITA ", # Prefijo para los nombres de las nuevas columnas
values_from = GLUCOSA) # Columna que llenará los valores
datatable(formato_ancho)# Convertir a formato largo
formato_largo <- formato_ancho %>% # tidyr
pivot_longer(
cols = starts_with("VISITA"), # Columnas a pivotar
names_to = "VISITA", # Nueva columna para los nombres
values_to = "GLUCOSA") # Nueva columna para los valores
datatable(formato_largo)Para ilustrar el funcionamiento, se crea una segunda tabla de datos llamada Base_facultades. Es importante tener en cuenta que para unir tablas es necesario tener una llave, es decir, una o varias variables (columnas) que permitan identificar cada fila sin ambiguedad de manera exclusiva presente en las tablas que se desean unir. En este caso, se empleara la variable FACULTAD.
Base_facultades <- data.frame(
FACULTAD = c("Ingeniería", "Medicina", "Ciencias humanas", "Arquitectura","Administración"),
CAMPUS = c("Central", "Norte", "Central", "Oeste", "Este"),
DIRECTOR = c("Juan Pérez", "María Gómez", "Luis Torres", "Ana Ramírez","Oscar Jimenez"))
datatable(Base_facultades)A continuación se presentan la 4 formas de unir tablas de datos usando el paquete base, y Las funciones left_join(), right_join(), inner_join() y full_join() del paquete dplyr.
left_result <- merge(Base_select, Base_facultades, by = "FACULTAD", all.x = TRUE) # base
left_result <- left_join(Base_select, Base_facultades, by = "FACULTAD") # dplyr
datatable(left_result)right_result <- merge(Base_select, Base_facultades, by = "FACULTAD", all.y = TRUE) # base
right_result <- right_join(Base_select, Base_facultades, by = "FACULTAD") # dplyr
datatable(right_result)inner_result <- merge(Base_select, Base_facultades, by = "FACULTAD", all = FALSE) # base
inner_result <- inner_join(Base_select, Base_facultades, by = "FACULTAD") #dplyr
datatable(inner_result)full_result <- merge(Base_select, Base_facultades, by = "FACULTAD", all = TRUE) # base
full_result <- full_join(Base_select, Base_facultades, by = "FACULTAD") # dplyr
datatable(full_result)Una ventaja de este paquete, es que permite aplicar múltiples funciones usando el operador pipe %>%, lo cual reduce las líneas de código y simplifica la manipulación de las tablas de datos.
Supongamos que se quiere:
library(dplyr)
# Filtrar, transformar y resumir la tabla
resultado <- Base_prueba_aspirantes %>%
# 1. Filtrar estudiantes con PTOTAL > 650
filter(PTOTAL > 650) %>%
# 2. Crear una nueva columna categorizando según PTOTAL
mutate(CATEGORIA = ifelse(PTOTAL > 750, "Alto", "Bajo")) %>%
# 3. Agrupar por facultad y calcular valores deseados
group_by(FACULTAD) %>%
summarise(
PROMEDIO_PTOTAL = round(mean(PTOTAL, na.rm = TRUE),2),
PUNTAJE_ALTO = sum(CATEGORIA == "Alto"),
NUMERO_ESTUDIANTES = n()
) %>%
# 4. Ordenar por promedio de PTOTAL en orden descendente
arrange(desc(PROMEDIO_PTOTAL))
datatable(resultado)